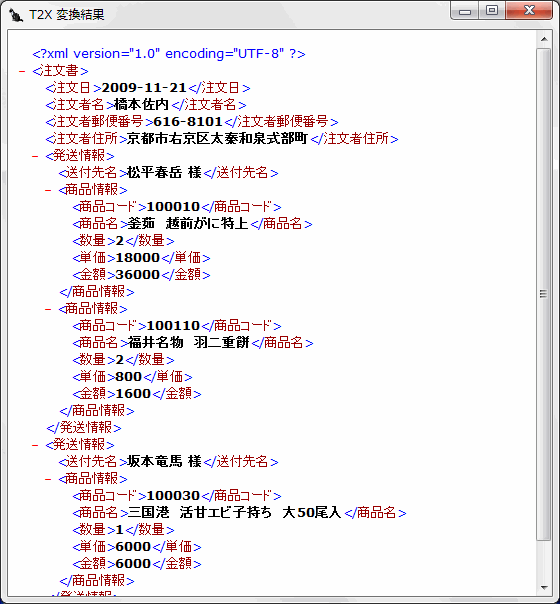
第4章 詳細T2Xスタジオ
T2XスタジオはT2Xコンバータで使用するテキストファイルをXMLに変換する規則を、分かり易く効率的に作成するためのソフトウェアです。
- 4.1 T2Xスタジオの起動と各部の名称
- 4.2 メインメニュー
- 4.3 メインツールバー
- 4.4 XMLノードビュー
- 4.5 XMLノード編集ペイン
- 4.6 文字列抽出規則リスト
- 4.7 文字列抽出規則編集ペイン
- 4.8 デバッグペイン
4.1 T2Xスタジオの起動と各部の名称
T2Xスタジオの起動方法と各部の名称は次の通りです。
T2Xスタジオの起動方法
T2Xスタジオを起動するには、インストールフォルダにあるT2XStudio.exeを開きます。
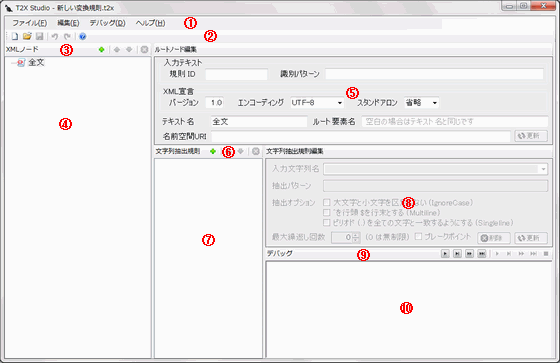
各部の名称
各部の名称は次の通りです。
①メインメニュー
②メインツールバー
③XMLノードツールバー
④XMLノードビュー
⑤XMLノード編集ペイン
⑥文字列抽出規則ツールバー
⑦文字列抽出規則リスト
⑧文字列抽出規則編集ペイン
⑨デバッグツールバー
⑩デバッグペイン
4.3 メインツールバー
メインツールバーにはメインメニューの項目のうちで良く使われるものがボタンとして登録されています。
 新規作成 新規作成 |
新しい変換規則を作成します。 |
 開く 開く |
既存の変換規則ファイルを開きます。 |
 上書き保存 上書き保存 |
編集中の変換規則をファイルに上書き保存します。 |
 元に戻す 元に戻す |
編集中の変換規則を元に戻します。 |
 やり直し やり直し |
編集中の変換規則で元に戻した操作をやり直します。 |
 操作マニュアル 操作マニュアル |
操作マニュアルを表示します |
4.4 XMLノードビュー
XMLノードビューには、テキストを変換して作るXMLの構造が表示されます。形式はDOMツリーに準じ、ノードビューのノードがDOMのノードに対応していますがDOMとは同一ではありません。
ノードには次の4つがあります。
| ルートノード | XMLの文書オブジェクトに対応します。DOMではこの下にXML宣言、ルート要素が配置されますが、T2Xスタジオではこれらをルート項目として纏めて設定するようにしています。 |
| 属性ノード | 属性ノードは親ノードである要素ノードの属性となります。 |
| テキストノード | テキストノードは親ノードである要素ノードのテキストとなります。 |
| 要素ノード | 要素ノードは親ノードである要素ノードの子要素となります。 |
XMLノードツールバー
XMLノードビューの上にはノードビューを操作するためのツールバーがあります。各ボタンの機能は次の通りです。
 子に追加 子に追加 |
選択したノードの下に新しいノードを追加します。 |
 上に移動 上に移動 |
選択したノードを上に移動します。 |
 下に移動 下に移動 |
選択したノードを下に移動します。 |
 ノードを削除 ノードを削除 |
選択したノードを削除します。 |
4.5 XMLノード編集ペイン
XMLノード編集ペインでは、選択したノードビューのノードに対応した項目を編集します。選択したノードビューのノードがルートノードの場合とその他の場合では、XMLノード編集ペインに表示される内容が異なります。
ルートノードの場合
ルートノードを選択した場合にはXMLノード編集ペインはXML宣言やルート要素に関する設定を行います。
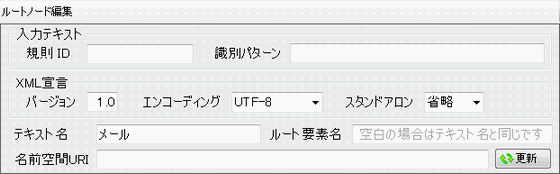
| 規則ID | T2Xコンバータに複数の変換規則を登録して変換を実行する場合に、どの変換規則が適用されたかを識別するためのIDです。任意の文字列を設定して下さい。 |
| 識別パターン | T2Xコンバータで変換する入力テキストが正しいファイルであるかを識別するための正規表現パターンです。入力テキストにこのパターンとマッチする部分があれば、正しいテキストと看做します。 |
| バージョン | XMLのバージョンです。1.0固定です。 |
| エンコーディング | XMLの文字エンコーディング指定です。省略を選ぶとエンコーディング指定は出力されません。 |
| スタンドアロン | XMLのスタンドアロン宣言です。省略を選ぶとスタンドアロン宣言は出力されません。 |
| テキスト名 | 入力テキストに任意に名前を付けて下さい。 |
| ルート要素名 | ルート要素名を指定します。省略するとテキスト名と同じになります。 |
| 名前空間URI | このXML文書のデフォルトの名前空間URIを指定します。省略した場合はデフォルトの名前空間URIは宣言されません。 |
| [更新]ボタン | ルートノードに関する設定を更新します。 |
ルートノードの更新を行うと、ノードビューのルートノードには「テキスト名<ルート要素名>」と表示されます。
ルート以外のノードの場合
ルート以外のノードを選択した場合にはXMLノード編集ペインはノードの属性、ノードのテキストまたは子要素に関する設定を行います。
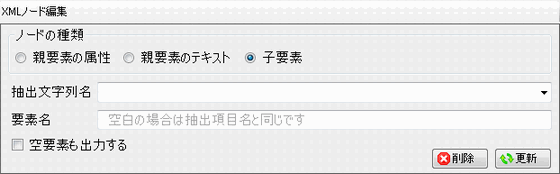
| ノードの種類 | 親要素の属性、親要素のテキスト、子要素のいずれかを選択します。 |
| 抽出文字列名 | 親ノードには一つの文字列が割り当てられています。ルートノードでは入力テキスト全体が割り当てられています。各ノードでは後述の文字列抽出規則により、割り当てられた文字列を名前を付けて幾つかの部分文字列に分解します。この部分文字列はノードの属性、テキストとして使われるか、子ノードの文字列として割り当てられてさらに小さな部分文字列に分解されます。この部分文字列に付けられた名前を抽出文字列名といいます。 このノードに割り当てる抽出文字列名をコンボボックスより選択します。この抽出文字列名から得られる文字列がノードに割り当てられます。割り当てられた文字列はノードの種類が属性の場合は属性値となり、テキストの場合はテキスト文字列となります。ノードの種類が要素の場合は、ノードが子要素を持たない場合は要素のテキストとなります。要素が子要素を持つ場合は、さらに部分文字列に分解して孫要素に使用できます。 |
| 要素名または属性名 | ノードの種類が属性の場合は属性名を指定します。ノードの種類が要素の場合は要素名を指定します。いづれの場合も省略可能で、省略すると抽出文字列名と同じになります。ノードの種類がテキストの場合は指定できません。 |
| 空要素も出力する | ノードの種類が要素の場合に、空要素であっても出力するかを指定します。 |
| [削除]ボタン | このXMLノードを削除します。 |
| [更新]ボタン | XMLノードに関する設定を更新します。 |
XMLノードの更新を行うと、ノードビューのノードには「抽出文字列名<要素名>」と表示されます。
4.6 文字列抽出規則リスト
ノードビューのノードには入力テキストの一部である文字列が割り当てられています。文字列抽出規則リストには、ノードビューで選択したノードに割り当てられている文字列より部分文字列を抽出するための方法の一覧が表示されます。ノードビューのノードに割り当てられた文字列からは指定した方法で部分文字列を抽出し、またその部分文字列を用いてさらに部分文字列を抽出することができます。文字列の抽出はこの文字列抽出規則リストの表示順に行われます。
文字列抽出規則ツールバー
文字列抽出規則リストの上には文字列抽出規則リストを操作するためのツールバーがあります。各ボタンの機能は次の通りです。
| 追加 |
文字列抽出規則リストの最後に新しい抽出規則を追加します。 |
| 上に移動 |
選択した抽出規則を上に移動します。 |
| 下に移動 |
選択した抽出規則を下に移動します。 |
| 規則を削除 |
選択した抽出規則を削除します。 |
4.7 文字列抽出規則編集ペイン
文字列抽出規則編集ペインでは、選択した文字列抽出規則リストの規則に対応した文字列抽出規則を編集します。
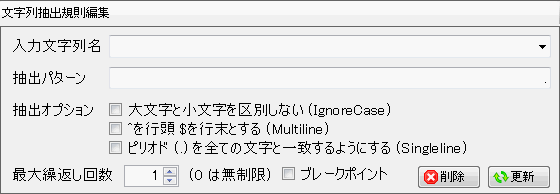
| 入力文字列名 | 文字列抽出のソースとなる入力文字列の名前をコンボボックスより選択します。入力文字列名はノードビューのノードに割り当てられている文字列の名前または、文字列抽出規則リストの現在の規則よりも上の抽出規則で作られて部分文字列の名前です。 |
| 抽出パターン | 入力文字列より部分文字列を抽出するためのパターンです。このパータンは正規表現のパターンです。T2Xで用いている正規表現では名前を付けたグループを作ることができます。このグループで部分文字列が抽出され、この部分文字列にはグループ名が文字列の名前として付けられます。正規表現に関しては別の章で概説していますので参考にして下さい。 |
| 抽出オプション | 正規表現パターンでマッチングさせる場合、次の3つのオプションが指定できます。 1.大文字と小文字を区別しない (IgnoreCase) 通常は大文字と小文字を区別してマッチングします。このオプションを指定すると大文字と小文字を区別しません。 2.^を行頭 $を行末とする (Multiline) 通常は ^ はテキストの先頭、$ はテキストの末尾を現しますが、このオプションを指定すると各行の行頭と行末を現します。 3.ピリオド (.) を全ての文字と一致するようにする (Singleline) 通常ピリオドは改行を除く任意の1文字を現しますが、このオプションを指定すると、改行を含む任意の1文字を現します。 |
| 最大繰返し回数 | 入力文字列より抽出パターンにマッチングする文字列は複数個になる場合があります。複数回マッチした場合、マッチした回数だけXMLに出力されます。ここでマッチングさせる最大繰返し回数を指定することができます。この場合最大繰返し回数を超えるマッチングは無視されます。指定回数が0の場合は回数無制限になります。 |
| ブレークポイント | デバッグテスト時のブレークポイントに設定します。ブレークポイントに設定すると、このポイントで文字列の抽出状態を確認することができます。 |
| [削除]ボタン | この文字列抽出規則を削除します。 |
| [更新]ボタン | この文字列抽出規則を更新します。 |
4.8 デバッグペイン
デバッグとは、作成した変換規則が正しく動作するかを確認するものです。デバッグペインには各文字列抽出規則の実行結果を確認するために、文字列抽出規則の入力文字列を表示し、パターンにマッチした文字列を緑色の背景色にして表示します。またグループにマッチした部分は赤色の文字で表されます。
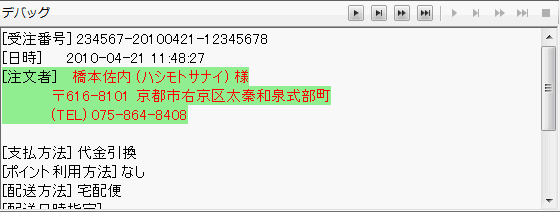
デバッグの準備
デバッグにはテスト用のテキストファイルが必要です。これを用いて変換のテストを行います。また変換結果の出力先の指定も必要です。メインメニューの「デバッグ(D)」から「テスト用ファイルの設定(T)」を選択します。
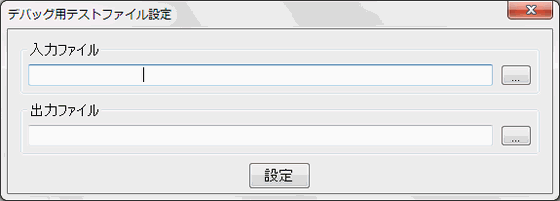
テスト用の入力ファイルと、変換結果の出力ファイルを設定して下さい。
デバッグツールバー
デバッグペインの上にはデバッグ操作を行うためのツールバーがあります。各ボタンの機能は次の通りです。
 最初の抽出を実行 最初の抽出を実行 |
ルートノードにある最初の文字列抽出規則を実行します。 |
 最初から選択規則まで実行 最初から選択規則まで実行 |
最初から、文字列抽出規則リストで選択されている文字列抽出規則までを実行します。 |
 最初のブレークポイントまで実行 最初のブレークポイントまで実行 |
最初から、ブレークポイントの設定されている最初の文字列抽出規則までを実行します。 |
 最後まで実行 最後まで実行 |
最初から最後まで、全ての文字列抽出規則を実行します。 |
 次の抽出を続行 次の抽出を続行 |
現在の状態から、次の文字列抽出規則を実行します。 |
 選択規則まで続行 選択規則まで続行 |
現在の状態から、文字列抽出規則リストで選択されている文字列抽出規則までを実行します。 |
 次のブレークポイントまで続行 次のブレークポイントまで続行 |
現在の状態から、ブレークポイントの設定されている次の文字列抽出規則までを実行します。 |
 最後まで続行 最後まで続行 |
現在の状態から最後まで、全ての文字列抽出規則を実行します。 |
 デバッグを終了 デバッグを終了 |
デバッグを終了します。 |
最後までデバッグを行い完了すると、
と表示されます。「はい」を押すとXMLファイルが所定の場所に作成され、変換結果ウィンドウに変換後のXMLファイルの内容を表示します。